
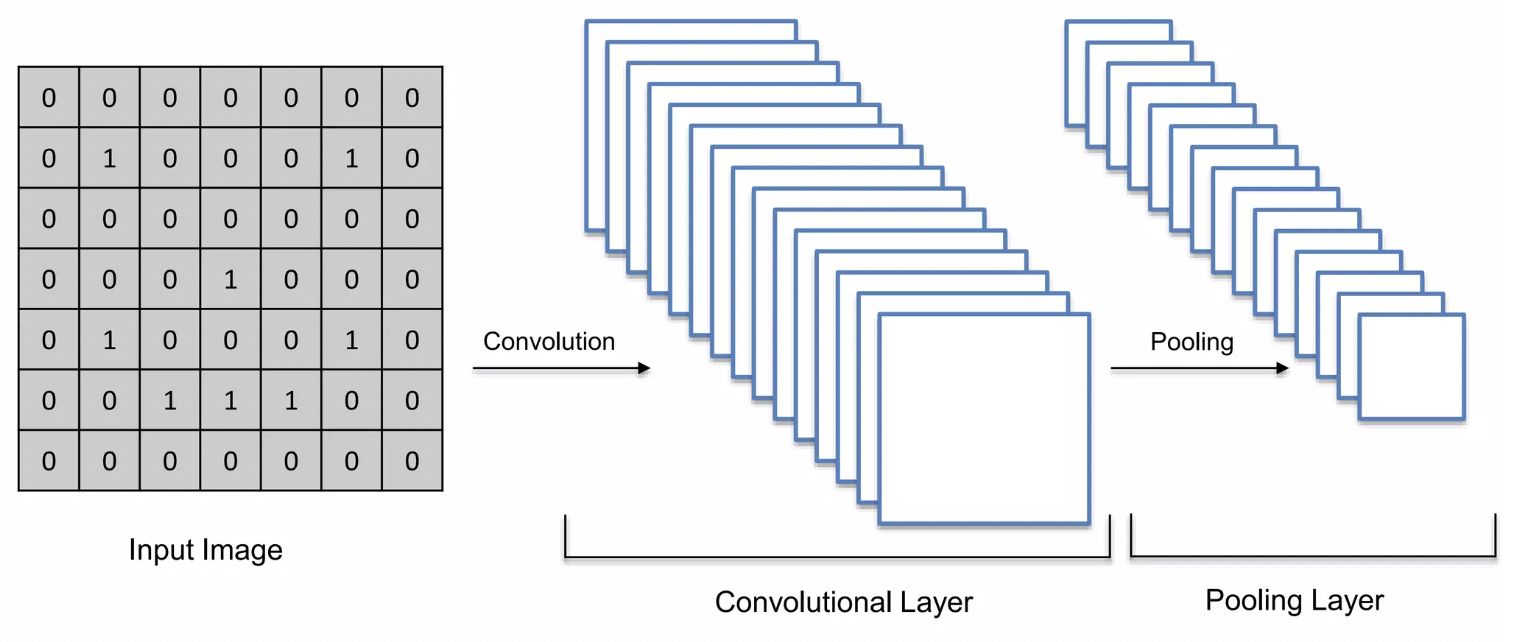
Step1 : Convolution Operation
Convolution Operation
Feature Detector를 이용해서 Input Image에서 중요한 특징을 찾아내서 Feature Map을 만들기 위함
(The primary purpose of a Convolution is to find features in the image, using the Feature Detector, put them into a Feature map and by having them in a Feature Map. It preserves the spacial relationships between pixels which is very important for us.)
- feature detector = kernel = filter (보통 3*3 size를 사용)
- stride 간격이 증가하면 → feature map은 작아진다.
- 이미지가 작아지면 더 처리하기 쉽고 속도도 빨라진다.


Feature Detector
같은 이미지에, 다른 feature detector를 사용 → 같은 이미지의 다양한 feature map을 얻을 수 있다. (각각 이미지의 다른 특징을 찾아주는 결과를 얻음)
- Sharpen: Feature detector 한 가운데에 main pixel인 5가 있고, 그 주변의 pixel을 줄이기 위해서 -1로 둘러싸고 있다. 사진을 선명하게 만들어준다.

- Blur: 똑같은 중요성을 중심 주변에 있는 모든 pixel에 부여해서(같은 1값을 중심에 동일하게 배치), 모두 합치게 되면 blur가 된다.

- Edge Enhance: -1, 1이 있고 주변에는 0이 존재하며, 이 0은 삭제하는 역할을 한다. 즉, 가운데 있는 main pixel만 제외하고 주변에 있는 pixel을 제거하여 테두리만 남겨둔다.

- Edge Detect: -4가 중간에 위치하여, 중간에 있는 pixel을 줄여준다. 즉, 가운데 pixel의 채도를 줄여주고 주변의 1값을 이용하여 주변 채도를 높여서 테두리를 감지한다.

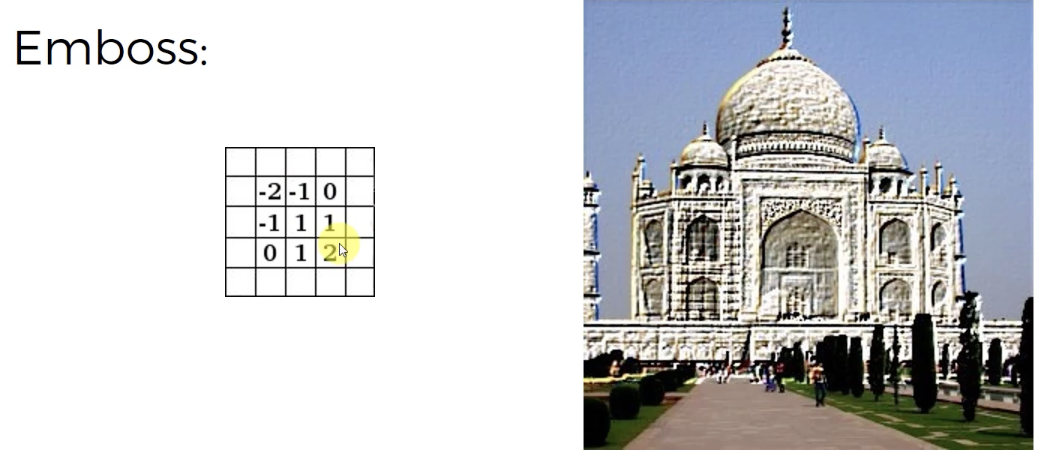
- Emboss: 왼쪽상단의 숫자들과 오른쪽하단의 숫자의 부호가 반대이므로, 비대칭을 만들어준다. 물체가 사진밖으로 볼록하게 튀어나온 것 같이 만들어준다.
Step1-2 : ReLU Layer
Rectifier Linear Unit

- 원래의 이미지는 비선형적(highly non-linear)이며, 특히 배경이나 이미지 속의 다른 객체를 인식하면 더 많은 비선형 요소(non-linear element)가 있다.
- 인접한 pixel들 값의 차이 → 비선형성을 유발!!
- convolution operation → feature detector를 적용해서 feature map 형성의 과정을 거치면서 이미지가 선형적(linear)이 될 위험이 생긴다
- 따라서, 원래의 이미지가 가진것처럼 선형성(linearity)을 끊어줘서 비선형적이게 만들어야 한다. (Purpose of ReLU: break up the linear)
- 선형성을 끊는 과정:
이미지의 검정부분은 negative values, 흰색부분은 positive values를 가지고 있다면,

Rectifier Linear Unit(ReLU)를 통해서 negative values를 제거(negative values는 모두 0이 되기 때문)하여 only non-negative values 만 남긴다.

Step2 : Pooling
Pooling
같은 물체를 담고 있는 이미지라도 각 이미지가 회전, 찌그러짐, 멀리 떨어짐 등등의 이유로 다르게 존재할 수 있다. 하지만 신경망은 차이가 존재하는 각각의 이미지에서 같은 객체라고 추론할 수 있어야 한다. 즉, 특징 자체가 약간 왜곡되어 있더라도, 신경망은 그 특징을 찾을 수 있을 정도의 융통성은 있어야 한다. 이 융통성을 위해서 pooling 과정이 존재.
- (2*2) pixel box로 feature들을 pooling → 4개의 pixel중 3개를 무시하기 때문에 정보는 25%만 유지되므로 찾는 정보가 아닌 것들의 75%를 제거하게 된다.

- feature map 의 size는 줄어들지만, 특징은 없어지지 않는다.
- pooling = down sampling
Step3 : Flattening
Flattening
나중에 Artificial Neural Network에 input으로 넣기 위해서 완성된 Pooled Feature Map을 한 행씩 펼쳐서(row-by-row) 하나의 열로 만든다.
⇒ ANN Layer의 Input이 될 하나의 거대한 input vector 탄생

Step4 : Full Connection
Fully Connected Layer
ANN의 Hidden Layer = CNN의 Fully Connected Layer
- ANN의 Hidden Layer는 ‘fully connected’될 필요가 없었지만, CNN에서는 ‘fully connected’ 를 사용한다.
- ANN의 목적은 특징을 더 잘 예측할 수 있는 속성끼리 결합하는 것이다. 즉, ANN은 속성과 특징을 다루며 새로운 속성을 만들고 속성을 결합해서 예측을 더 잘 할 수 있게 해준다.
(ANN has a purpose of dealing with attributes and coming out, dealing with features and coming up with new attributes and combining attributes together to even better predict things that we’re trying to predict.)
- Convolution Operation → Pooling → Flattening 과정을 거쳐서 feature만 추출해 둔 input vector를 ANN에 넣어서 좀 더 최적화(optimize)해서 예측을 더 잘 해보자!!

Output이 한 개 → 회귀(regression type), 수치 값(numerical value) 예측
Output이 두 개 → binary 이므로 1은 ‘Dog’, 0은 ‘Cat’ 으로 적용해도 결과예측 가능
Output이 여러개 → categorical classification, 모든 category마다 neuron이 있어야 함
Final Fully Connected Layer
Final neuron(Dog, Cat)들은 Fully Connected Layer에서 어떤 neuron(숫자가 있는 초록원)의 정보를 가져와야 하는지 학습한다. (Back-propagation, Forward-propagation)
⇒ 즉, Final neuron은 FC layer에서 어떤 neuron의 말을 들을지 결정해 나가는 것

- voting → Final FC layer에 있는 neuron들은 voting을 할 수 있으며, 원 안의 값들이 neuron의 투표이다.
- Final neuron(Dog, Cat)에 연결 된 weights(보라색, 초록색 선)가 각 neuron의 voting의 가치(importance of votes)를 결정한다.
🏆 Summary
CNN STEP

- Apply multiple different feature detectors to an input image (we also called ‘filters’ to create these feature maps)
- On top of the Convolutional Layer, apply the ReLU to remove any linearity or increase non-linearity in the input images.
- Apply a Pooling Layer to Conv Layer → from every single Feature Map we create a Pooled Feature Map
[Advantages of Pooling Layer]
- Spatial Invariance(공간적 불변성, 이미지의 분포적인 특성은 이미지 어느 위치에서든 동일하다고 가정하는 것)
- Significantly reduce the size of the images
- Help with avoiding any kind of over fitting, because it just simply gets rid of a lot of data
- Flatten all of the Pooled images into one long vector (n*1)
- Input that into an Artificial Neural Network
- Final fully connected layer performs the voting towards the classes (Forward-propagation and Back-propagation)
- Weights are trained in the ANN but also the feature detectors are trained and adjusted in the same gradient descent process → Come up with the best Feature Maps
[The 9 Deep Learning Papers You Need To Know About]
 https://adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html
https://adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html
