
Self-organizing maps are even often referred to as Kohonen maps.
Un-supervised deep learning algorithm
SOMs의 목적
- reducing dimensionality (reduce amount of columns → 2-dimension으로 출력한다.)
- 매우 많은 columns와 dimensions 을 가진 complex dataset을 simplified map으로 만들어 준다.
- The map provides you with a two-dimensional representation of the exact same dataset → 읽기가 더 쉬워진다.
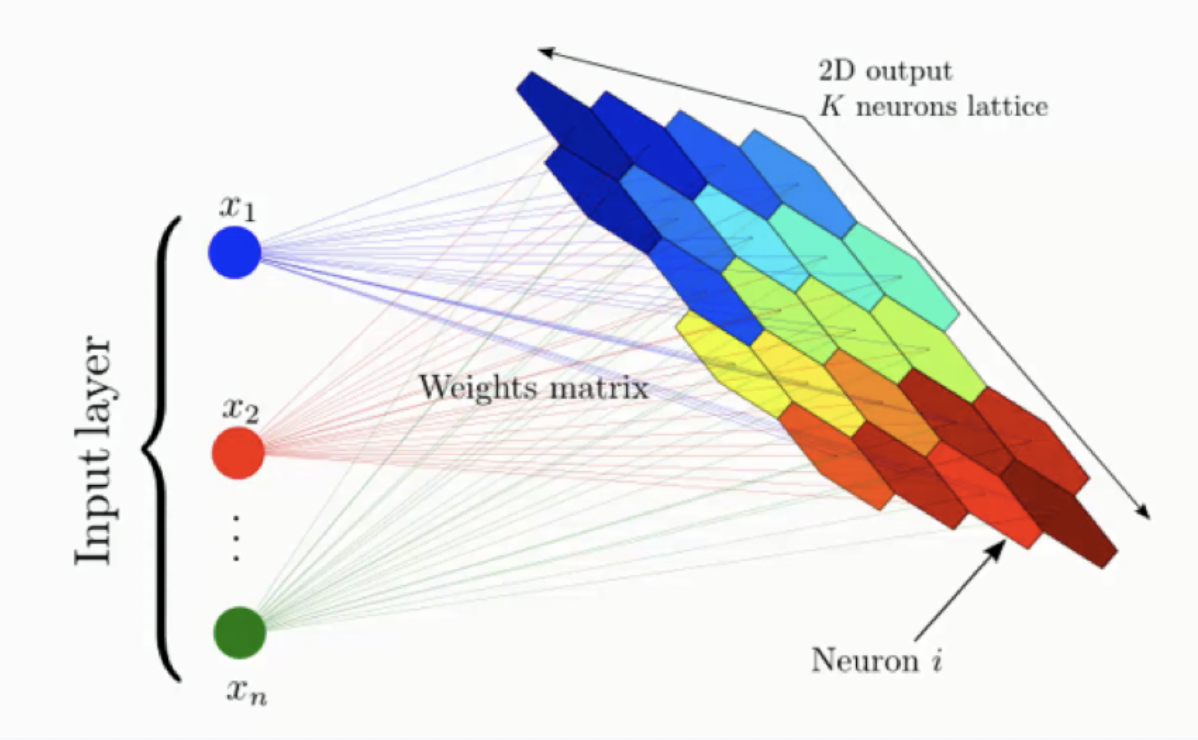
How do SOMs Learn?
input vector - 3개의 feature 존재(3개의 columns → 3 dimension) & output vector - 9개의 node 존재(2 dimensino)
데이터 셋의 차원을 줄이기 위해 존재, 따라서 3-Dim 을 2-Dim으로 줄이는 것
- 노드로 이어지는 3개의 synapses, 각각의 synapse 에는 weights 가 할당되어 있다.
- output node의 값은 activation function 이후의 결과를 뜻하는게 아니라, 입력공간의 노드 좌표를 뜻한다. ( → these weights are the coordinate of this node in our input space)
- 즉, output node는 입력 공간의 가상의 데이터 포인트이며 실제로 존재하지는 않지만 안에 들어가려고 노력하는 값이다. ( → imaginary datapoint in our input space, it’s trying to blending)
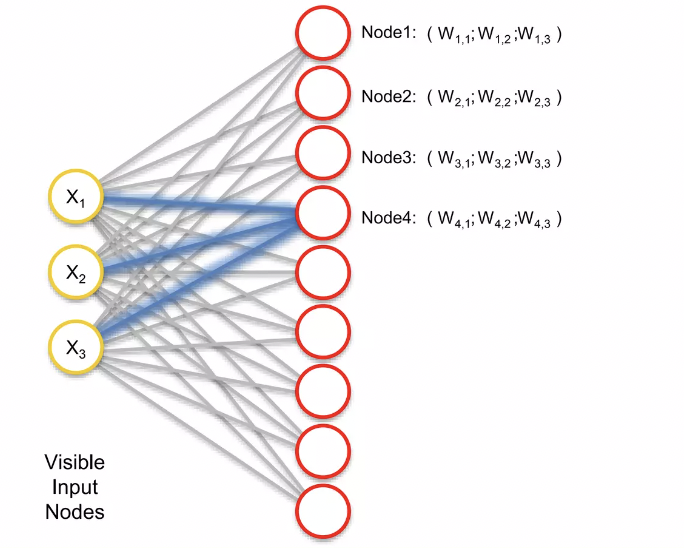
output node 중에서 dataset 의 각 행을 살펴보면서, 어떤 노드가 dataset 의 각 행에서 가장 가까운지 찾아내는 작업을 진행 ( → For each of the rows in our dataset, we’ll try to find the node closest to it.)
- euclidean distance 가까운 것을 구한다.
- node3가 0.4의 값으로 가장 가까운 거리임 → BMU(Best-matching-unit)
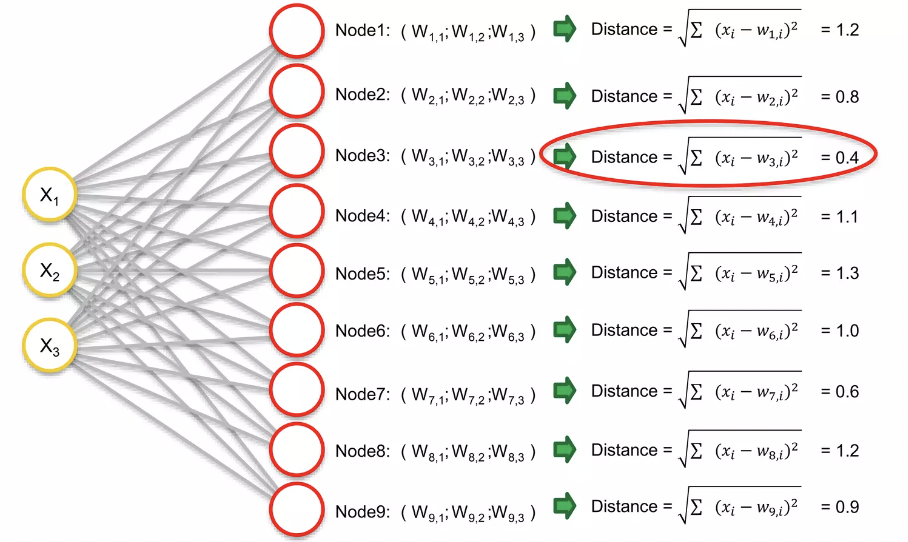
Self organizing maps 에서 나타내면 BMU는 아래와 같이 위치한다.
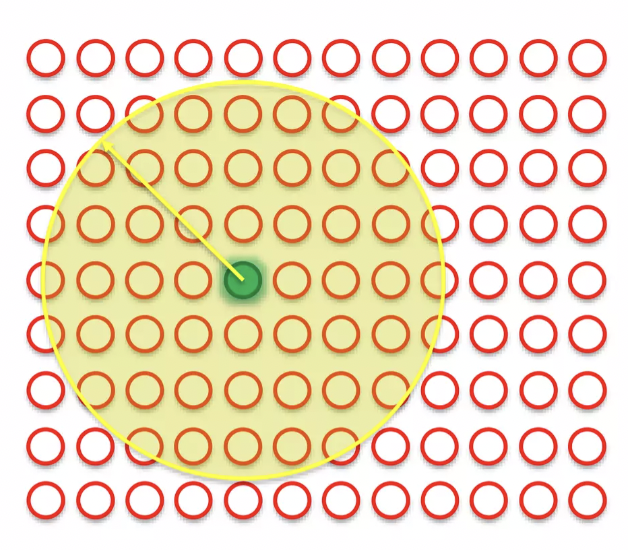
BMU에 weights를 update한다 (다른 데서의 weight 개념과는 달리, 여기서는 특정 노드의 성질을 의미; characteristics of specific node) → BMU를 current row로 끌고 온다. 이 때 BMU에 인접한 다른 point들도 끌고오게 된다.
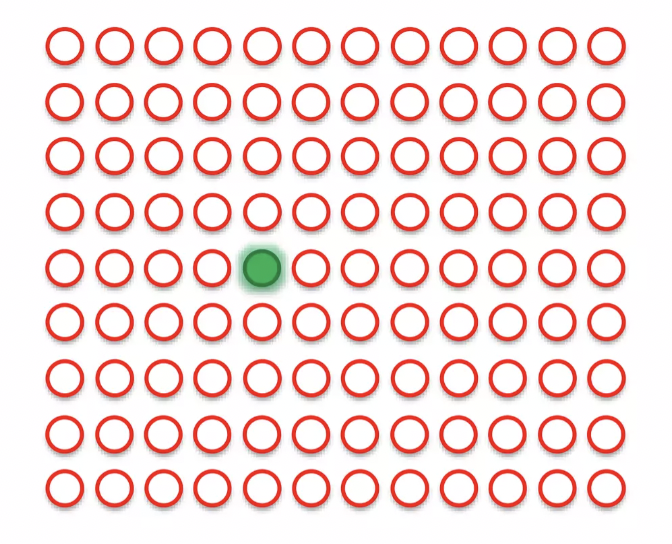
BMU 반경에 원을 그리고 SOMs 에서 이 반경안에 들어오는 every single point, every single node 의 weights를 업데이트해서 매치하는 행과 더욱 가까워지게 한다. (dragging each others)
업데이트 방식은 BMU에 가까운 노드일수록 weights는 더 무거워 진다. ( ⇒ 더 강하게 dragging 된다.)
Multiple Best-Matching Units?
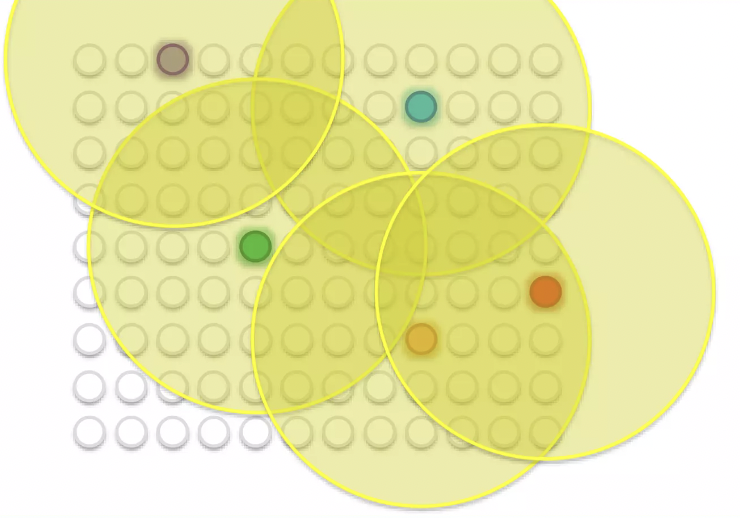
several BMU가 존재한다면?
- 각 BMU 주변에 특정한 영역이 설정되는데, 그 영역은 일정한 반경을 가지는 형태로 계산된다. (보통 시작 반경이 매우 크게 설정되기 때문에, 반경에 들어오지 못하는 값들은 SOMs 에서는 자주 일어나지 않는 일!)
- 모든 BMU 반경에 있는 값들은, 해당 BMU로 dragging 된다.
- epoch이 진행될 수록 kohonen algorithm에 의해서 반경은 점차 줄어들게 된다. (the radius become smaller) → dragging 되는 BMU 주변의 node들의 개수가 작아진다.
결과적으로 epoch이 진행될 수록 SOMs는 이렇게 확정된다.
After all the push and pull between the nodes and the different BMUs, we have come to a point where each node has been assigned a BMU

There are a few points to bear in mind hear:
SOMs retain the interrelations and structure(= topology) of the input dataset
SOMs uncover correlations that wouldn’t be otherwise easily identifiable(연관성과 유사성을 쉽게 찾아냄)
SOMs categorize data without the need for supervision(un-supervised learning 이므로, 뭘 찾아내야 할지 모를때도 연관성을 찾아낼 수 있음)
SOMs do not require target vectors nor do they undergo a process of backpropagation
There are lateral connections(수평연결; neural network type of connections이 아님, activation function 없음) between output nodes → 노드 사이에서 일어나는 유일한 일은 dragging 뿐이다!


