
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 경사하강법
- stemming
- VGGNet
- NMF
- Ann
- Python
- gaze estimation
- NER
- cross domain
- Transfer Learning
- Clustering
- SOMs
- Support Vector Machine
- Gradient Descent
- 자기조직화지도
- Logistic Regression
- 군집화
- textmining
- Binary classification
- ResNet
- BERT
- LSTM
- TFX
- AI 윤리
- nlp
- Attention
- Generative model
- MLOps
- tensorflow
- RNN
- Today
- Total
juooo1117
[Module 4] Supervised Learning: Gradient Descent 본문
[Module 4] Supervised Learning: Gradient Descent
Hyo__ni 2024. 1. 10. 10:50Part3. Gradient Descent
Batch gradient descent
파라미터를 업데이트하는 과정에서 전체 sample m개를 모두 고려해야 한다는게 단점이다.
즉, sample m개를 모두 accumulation 해서 파라미터를 1번 업데이트 하는 것!

이러한 문제를 해결하기 위해서 m을 극단적으로 줄여 1로 바꾼 알고리즘 → stochastic gradient descent (SGD)
빠르게 iteration을 돌 수 있다는 장점이 있지만, 각 sample 하나하나마다 계산해서 파라미터를 계산하기 때문에 noise의 영향을 많이 받는다는 단점이 있다.
따라서 수렴하는 과정에서 많은 Oscillations 이 발생한다.
Limitation: Local Optimum
SGD: very popular method but tends to be slow and difficult to reach the minimum
saddle point 처럼 어느 한 방향으로 수렴하게 될 때 gradient 값이 0이 되어서 local optimum 에 빠지게 되는 지점들이 다수 존재함.
이러한 suboptimal 한 문제점들을 해결하기 위해서 gradient descent algorithm의 변형이 많이 등장하였다.
→ 대표적인 방식은 momentum 을 이용하는 것!
(*momentum: 과거에 gradient가 업데이트 되어오던 방향 및 속도를 어느 정도 반영해서 현재 포인트에서 gradient가 0이 되더라도 계속해서 학습을 진행할 수 있는 동력을 제공하게 되는 것)

Method of momentum
Designed to speed up learning in high curvature and small/noise gradients
Exponentially weighted moving average of past gradients (low passing filtering)
SGD + momentum ⇒ Use a velocity as a weighted moving average of previous gradients
(만약 local minima 또는 saddle points 지점에서 gradient 값이 0이 되는 지점이 발생하더라도, 과거에 이어오던 momentum 값을 반영해서 계속해서 학습을 진행할 수 있도록 한다.)

Nesterov Momentum
Difference from standard momentum : where gradient is evaluated
기존의 방식의 경우에는 현재의 gradient step과 기존의 momentum step을 고려해서 실제 다음번의 actual step을 vector의 합으로 계산했지만, Nesterov Momentum update 방식에서는 미리 momentum step 만큼 이동한 지점에서 lookahead gradient step을 계산하고 이 두 vector 합으로 actual step을 계산한다.

AdaGrad
Adapts an individual learning rate of each direction
Allows an automatic tuning of the learning rate per parameter (각 방향으로의 learning rate를 조절하여 학습 효율을 높임)
- Slow down the learning rate when an accumulated gradient is large (gradient 값이 누적되면서 lr이 매우 작아짐 → 학습이 더 이상 일어나지 않을 것!)
- Speed up the learning rate when an accumulated gradient is small
RMSProp
attempts to fix the drawbacks of AdaGrad, in which the learning rate becomes infinitesimally small and the algorithm is no longer able learning when the accumulated gradient is large.
→ AdaGrad 처럼 극단적으로 gradient 값이 누적됨에 따라서 θ 값이 줄어드는 것이 아니라, 어느 정도 완충된 형태로 lr이 줄어듦
Adam (adaptive moment estimation)
RMSProp + momentum
1. Compute the first moment from momentum
2. Compute the second moment from RMSProp
3. Correct the bias (통계적으로 안정된 학습을 하기 위해서!)
4. Update the parameters
Learning rate
key hyper parameter for gradient-based algorithms ; need to gradually decrease learning rate over time
수렴단계마다 점차적으로 lr을 줄여나가게 되면 → 처음은 빠르게 수렴하고, 이후에 학습을 멈추지 않고 용이하게 할 수 있음
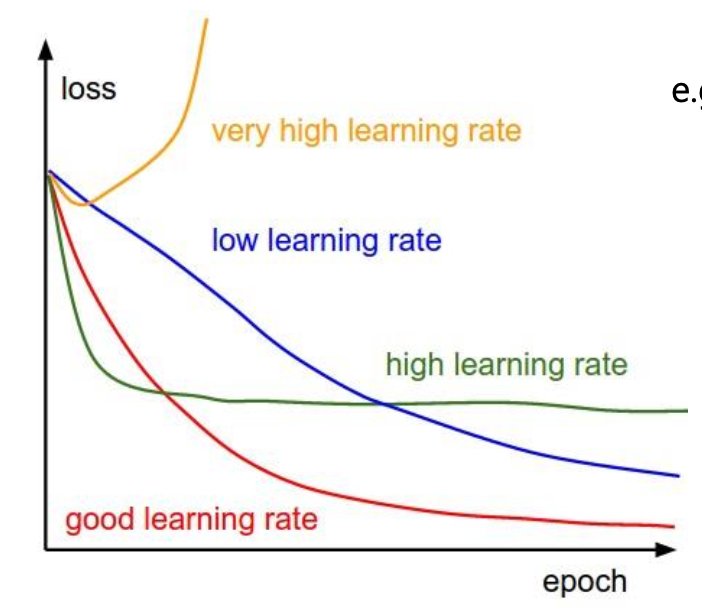
모델의 과적합(overfitting) 문제:
모델이 지나치게 복잡해서 학습 파라미터 숫자가 너무 많아서 제한된 학습 샘플에 너무 과하게 학습이 되는 것을 말한다.
If we have too many features, the hypothesis may fit the training set very well.
However, it may fail to generalize to new samples
to avoid overfitting,
- Reduce number of features : select which features to keep
- Regularization : keep the features but reduce magnitude/values of parameters & Simple hypothesis and less prone to overfitting and robust to noise
'Artificial Intelligence > LG Aimers: AI전문가과정' 카테고리의 다른 글
| [Module 4] Supervised Learning: Advanced Classification (2) | 2024.01.11 |
|---|---|
| [Module 4] Supervised Learning: Linear Classification (0) | 2024.01.10 |
| [Module 4] Supervised Learning: Linear Regression Model (2) | 2024.01.09 |
| [Module 3] Machine Learning 개론: Recent Progress of Large Language Models (1) | 2024.01.07 |
| [Module 3] Machine Learning 개론: Bias and Variance (1) | 2024.01.07 |



