
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- NMF
- Binary classification
- Clustering
- BERT
- cross domain
- TFX
- Attention
- gaze estimation
- nlp
- RNN
- Python
- Gradient Descent
- Support Vector Machine
- 군집화
- MLOps
- 자기조직화지도
- 경사하강법
- Ann
- AI 윤리
- SOMs
- ResNet
- stemming
- tensorflow
- textmining
- NER
- LSTM
- Logistic Regression
- VGGNet
- Generative model
- Transfer Learning
- Today
- Total
juooo1117
Word Embeddings - word2vec, Skip-Gram Model 본문
Word Embeddings
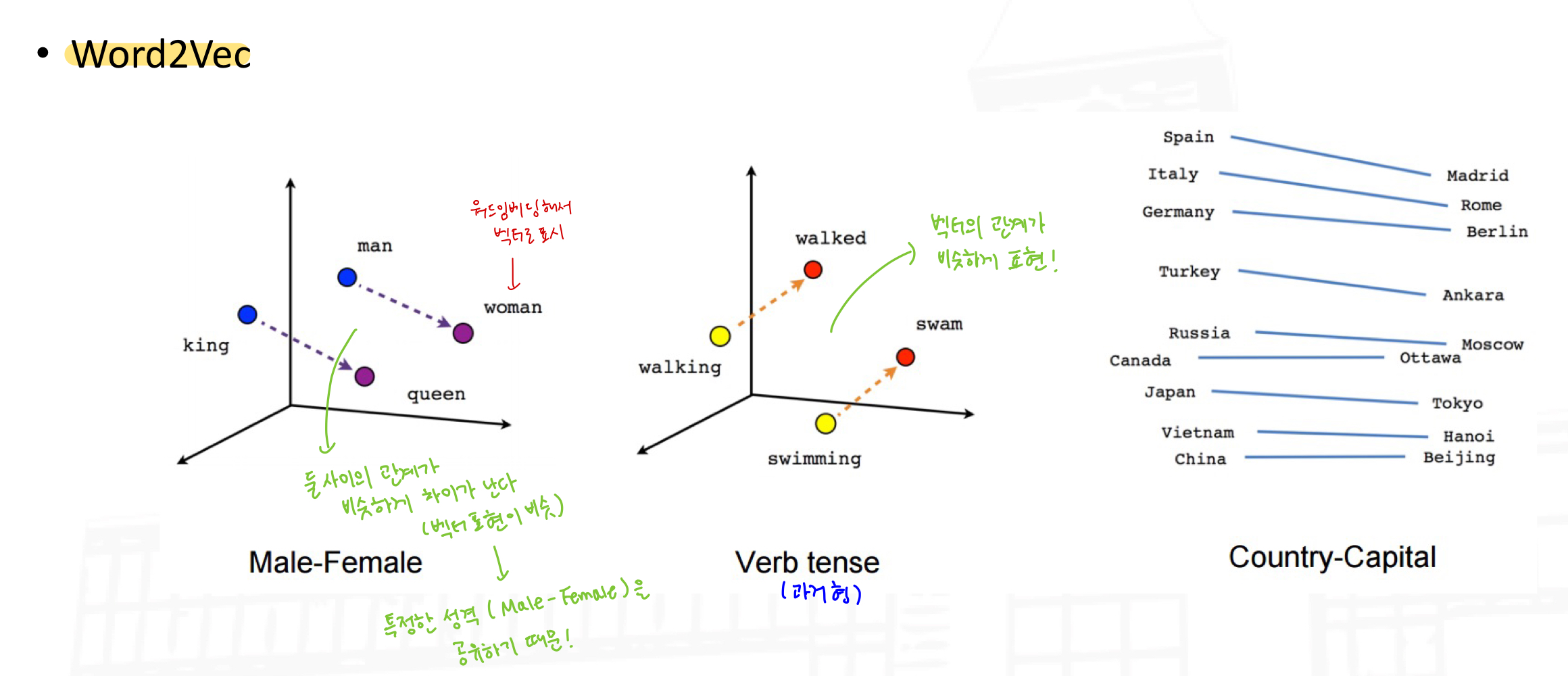
하나의 차원에 표현되었던 각 단어를 연속적인 숫자를 값으로 갖는 벡터 형식으로 표현하는 방식
Word2Vec : 하나의 단어를 표현하는 벡터를 구하기 위해 주변 단어를 활용해서 학습한다.
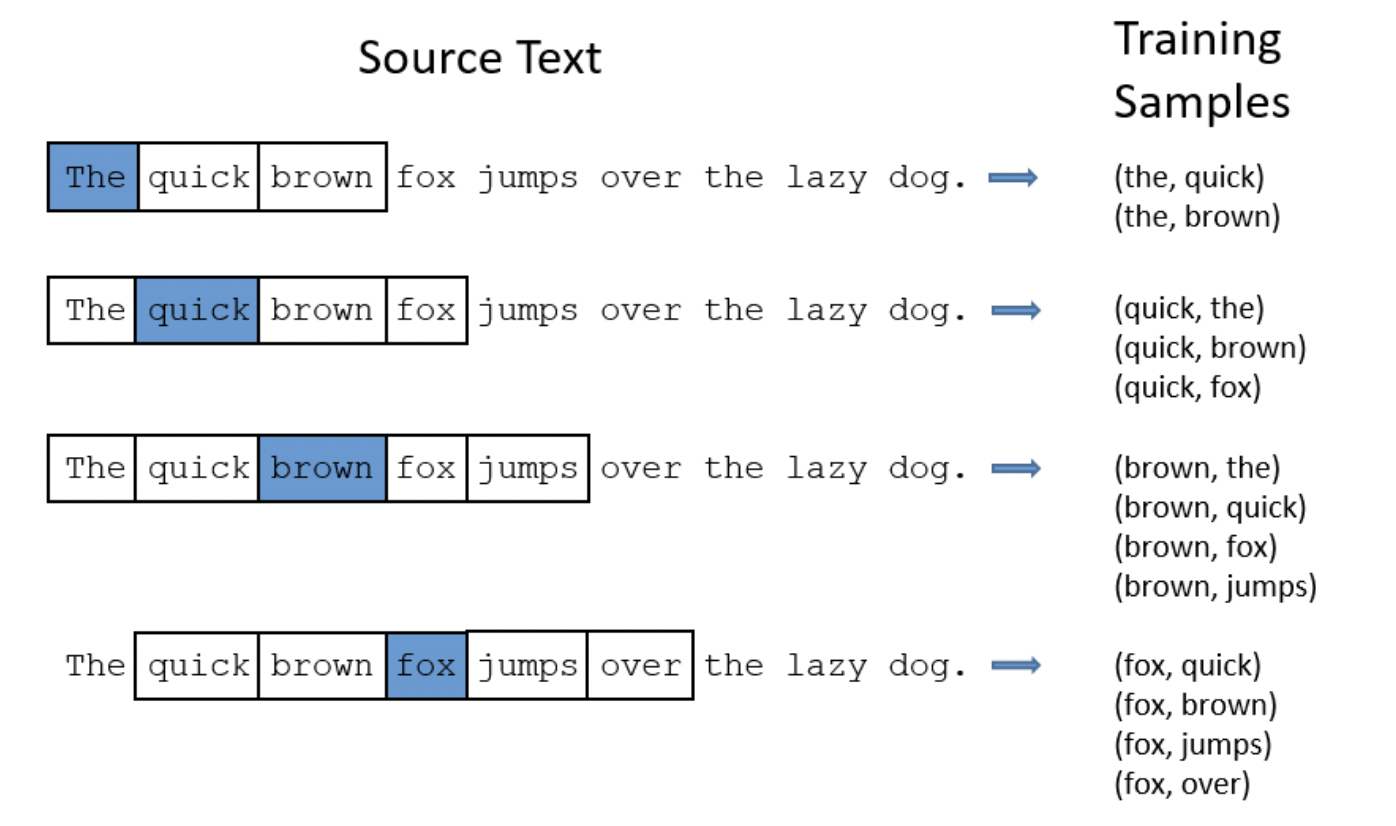
Skip-Gram Model
skip gram neural network architecture for Word2Vec
'The'가 입력으로 들어갔을 때, 주변의 단어(output)를 맞추는 것 ⇒ quick
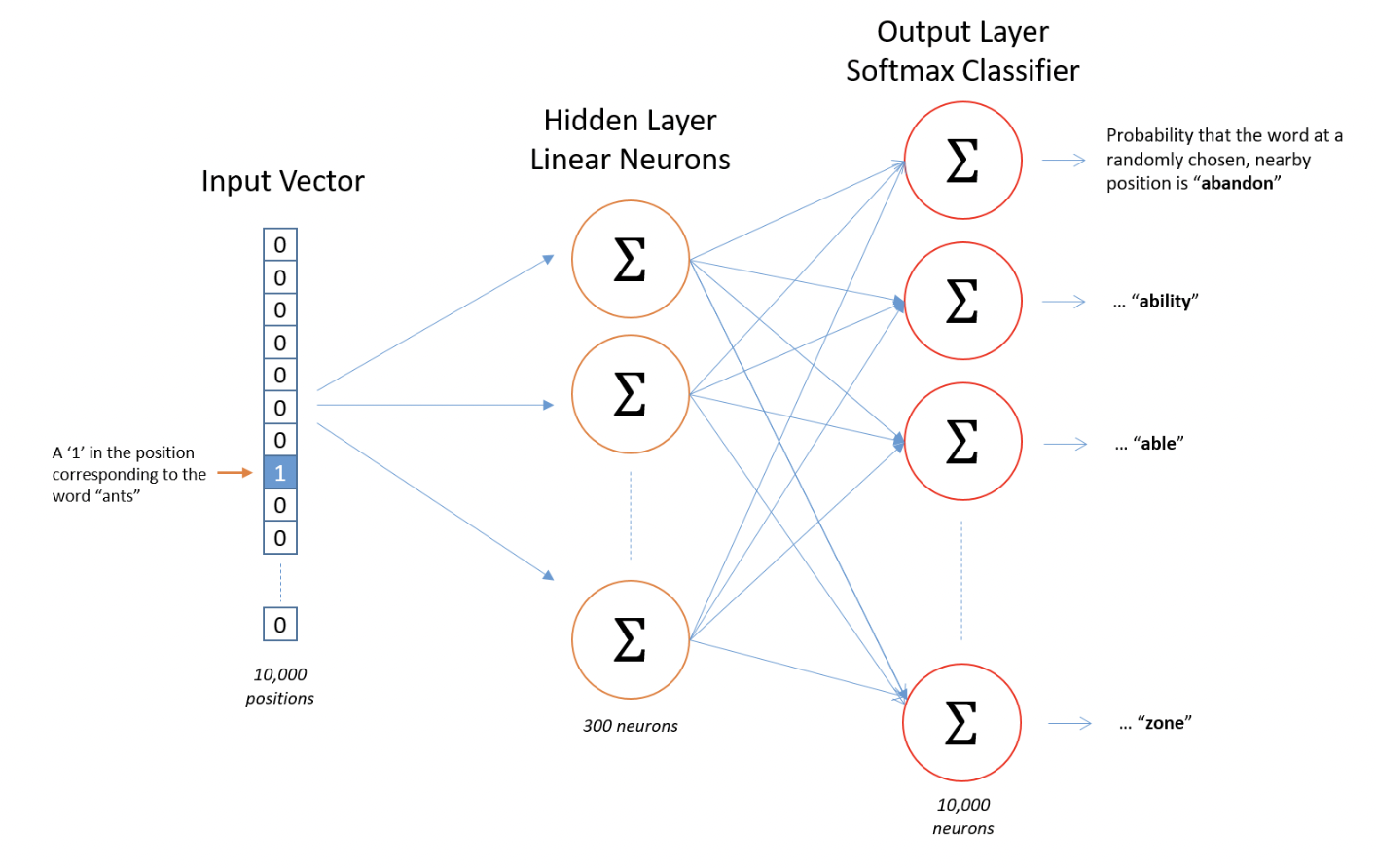
Model details
- input word를 one-hot vector 로 표현한다.
- This vector will have 10,000 components (one for every word in our vocabulary) and we’ll place a “1” in the position corresponding to the word “ants”, and 0s in all of the other positions.
- There is no activation function on the hidden layer neurons, but the output neurons use softmax.
- when evaluate the trained network on an input word, the output vector will actually be a probability distribution (i.e., a bunch of floating point values, not a one-hot vector)
word2vec with tensorflow
- bag-of-words 모델: 주변의 단어를 바탕으로 중간 단어를 예측. context는 현재(중간) 단어의 앞과 뒤의 몇몇 단어로 구성되어 있으며, 이 아키텍처는 콘텍스트의 단어 순서가 중요하지 않기 때문에 bag-of-words 모델이라고 불린다.
- skip-gram 모델: 동일한 문장 내의 현재 단어의 앞과 뒤 일정 범위 내의 단어를 예측한다. 즉, 단어 자체가 주어지면 단어의 context(또는 주변)을 예측하는 것이다.
두 가지 방법 중에서 skip-gram 접근 방식을 사용해서 tensorflow를 이용해서 코드로 구현해 보자
[Practice - tensorflow 'word2vec' tutorial]
https://github.com/juooo1117/practice_AI_Learning/blob/main/word2vec_Skip_GramModel.ipynb
'Artificial Intelligence' 카테고리의 다른 글
| DeepLearning for NLP - Tensorflow tutorial(Classify text with BERT) (0) | 2023.12.18 |
|---|---|
| Recommender System (1) | 2023.12.18 |
| Text Summarization (0) | 2023.12.14 |
| Named Entity Recognition using RFC(Random Forest Classifier) & CRF(Conditional Random Fields) (0) | 2023.12.14 |
| Movie genres - Clustering practice with NMF (0) | 2023.12.14 |



