
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- textmining
- 군집화
- NMF
- Binary classification
- Gradient Descent
- 경사하강법
- Logistic Regression
- LSTM
- Attention
- 자기조직화지도
- VGGNet
- ResNet
- Clustering
- tensorflow
- nlp
- TFX
- Generative model
- BERT
- Support Vector Machine
- RNN
- gaze estimation
- AI 윤리
- stemming
- Python
- SOMs
- cross domain
- Transfer Learning
- MLOps
- Ann
- NER
- Today
- Total
juooo1117
Named Entity Recognition using RFC(Random Forest Classifier) & CRF(Conditional Random Fields) 본문
Named Entity Recognition using RFC(Random Forest Classifier) & CRF(Conditional Random Fields)
Hyo__ni 2023. 12. 14. 14:44Named Entity Recognition
NER(Named Entity Recognition)의 목표는 Named Entity(이름을 가진 개체)를 Recognition(인식)하는 것을 의미하며, 개체명 인식이라고 한다. → NER is the process of locating and classifying named entities in text into predefined entity categories.
NER은 문장을 토큰 단위로 나누고, 이 토큰들을 각각 태깅(tagging)해서 개체명인지 아닌지를 판별하게 된다.
따라서, NER 작업을 위해 NE(인물이나 장소 등 고유명사)의 경계를 식별하고 해당 유형을 식별하는 두 가지 하위 작업으로 나눌 수 있다.
일반적으로 IOB 형식( = BIO format)을 사용하여 문장의 각 단어에 레이블을 지정하는 태거를 구축할 있다.
The IOB Tagging system contains tags of the form:
- B - {CHUNK_TYPE} – for the word in the Beginning chunk
- I - {CHUNK_TYPE} – for words Inside the chunk
- O – Outside any chunk
The IOB tags are further classified into the following classes –
- geo = Geographical Entity
- org = Organization
- per = Person
- gpe = Geopolitical Entity
- tim = Time indicator
- art = Artifact
- eve = Event
- nat = Natural Phenomenon
Dataset & Code
bavalpreet26/ner-using-crf (kaggle의 https://www.kaggle.com/datasets/abhinavwalia95/entity-annotated-corpus)
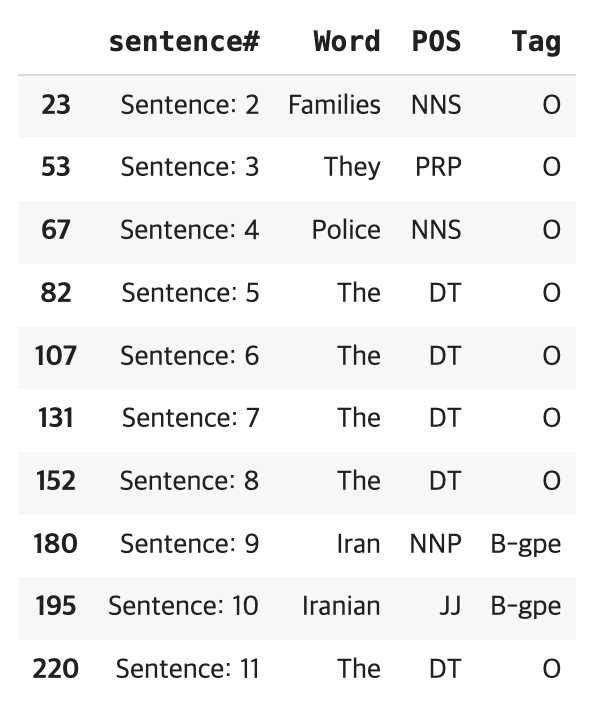
The dataset has the following columns or features -
- Index - Index numbers for each word [Numeric type]
- Sentence # - The number of sentences in the dataset (We will find the number of sentences below) [Numeric type]
- Word - The words in the sentence [Character type]
- POS - Parts Of Speech tags, these are tags given to the type of words as per the Penn TreeBank Tagset [Categorical type]
- Tag -The tags given to each word based on the IOB tagging system described above (Target variable) [Categorical type]
데이터셋을 확인해 보니, 대부분 geopolitical entities, geographical locations and person names 에 관련된 단어들로 이루어져 있다.
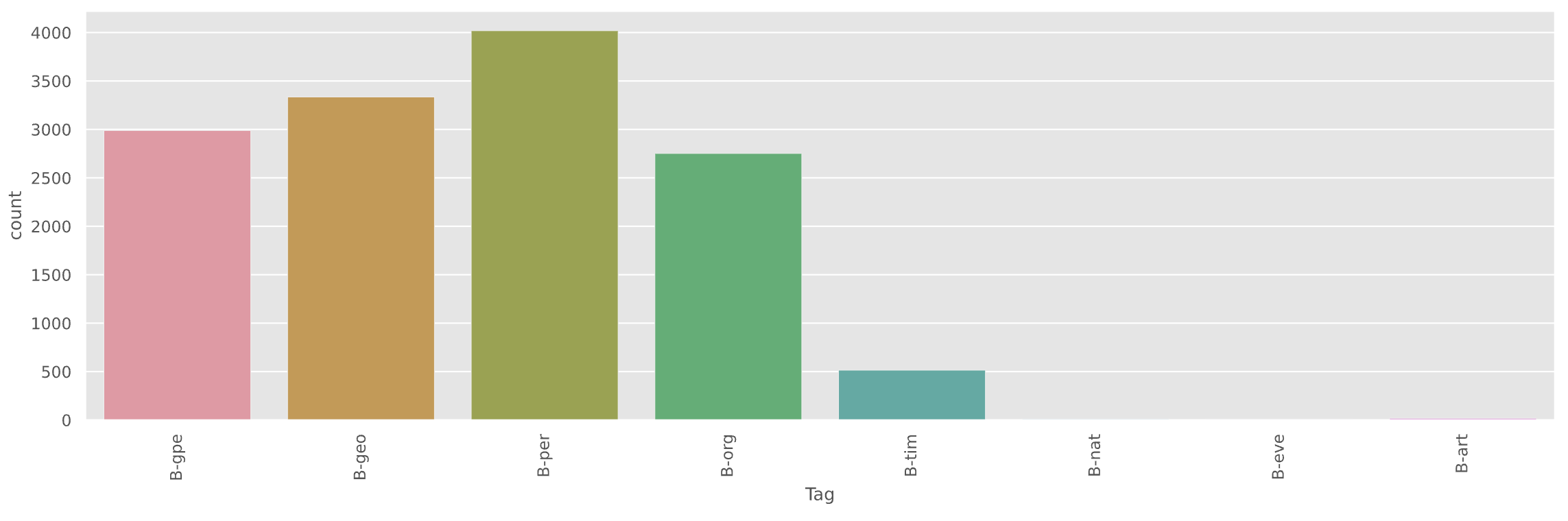
데이터셋의 POS 분포를 살펴보면 아래와 같이 이루어져 있다.
Modeling with Random Forest Classifier & Conditional Random Fields Classifier
Simple tree based models have been proven to provide decent performance in building NERC systems.
Random Forest being one of the most popular tree based models can learn the underlying rules according to which terms are tagged. → 간단한 트리 기반 모델은 NERC 시스템 구축에 적절한 성능을 제공하는 것으로 입증되었습니다. 가장 널리 사용되는 트리 기반 모델 중 하나인 Random Forest는 (태그가 지정된 용어에 따라서 기본 규칙을 학습할 수 있음)
Random Forest Classifier
Using 5 fold cross validation(k-fold cross validation; k겹 교차 검증, 집합을 체계적으로 바꿔가면서 모든 데이터에 대해 모형의 성과를 측정하는 검증 방식) as an input parameter to the classifier
→ divide the dataset into 5 subsets and train-test on them (training on one subset and test on the other, and repeat for every subset so that the classifier classifies correctly on average and the performance estimate is not overly optimistic)
def feature_map(word):
return np.array([word.istitle(), word.islower(), word.isupper(), len(word),
word.isdigit(), word.isalpha()])
words = [feature_map(w) for w in data["Word"].values.tolist()]
tags = data["Tag"].values.tolist()
pred = cross_val_predict(RandomForestClassifier(n_estimators=20),
X=words,
y=tags,
cv=5)Conditional Random Fields Classifier
- A Conditional Random Field (CRF) is a standard model for predicting the most likely sequence of labels that correspond to a sequence of inputs. (sequence를 고려하는 모델이다)
- It is a supervised learning method which has been proven to be better than the tree based models when it comes to NER. (NER에 있어서는 트리기반의 모델들보다 결과가 더 좋다)
- Whereas a discrete classifier predicts a label for a single sample without considering "neighboring" samples, a CRF can take context into account; e.g., the linear chain CRF (which is popular in natural language processing) predicts sequences of labels for sequences of input samples. (이웃에 뭐가 있는지, 즉 context를 고려하는 모델이다)
Since we need to take into account the context as well, we create features which will provide consecutive POS tags for each word. → context까지 고려하기 위한 feature set을 만들어야 한다.
# Feature set
def word2features(sent, i):
word = sent[i][0]
postag = sent[i][1]
features = {
'bias': 1.0,
'word.lower()': word.lower(),
'word[-3:]': word[-3:],
'word[-2:]': word[-2:],
'word.isupper()': word.isupper(),
'word.istitle()': word.istitle(),
'word.isdigit()': word.isdigit(),
'postag': postag,
'postag[:2]': postag[:2],
}
if i > 0:
word1 = sent[i-1][0]
postag1 = sent[i-1][1]
features.update({
'-1:word.lower()': word1.lower(),
'-1:word.istitle()': word1.istitle(),
'-1:word.isupper()': word1.isupper(),
'-1:postag': postag1,
'-1:postag[:2]': postag1[:2],
})
else:
features['BOS'] = True
if i < len(sent)-1:
word1 = sent[i+1][0]
postag1 = sent[i+1][1]
features.update({
'+1:word.lower()': word1.lower(),
'+1:word.istitle()': word1.istitle(),
'+1:word.isupper()': word1.isupper(),
'+1:postag': postag1,
'+1:postag[:2]': postag1[:2],
})
else:
features['EOS'] = True
return features
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
def sent2labels(sent):
return [label for token, postag, label in sent]
# creating the train and test set
X = [sent2features(s) for s in sentences]
y = [sent2labels(s) for s in sentences]
# creating the CRF model
crf = sklearn_crfsuite.CRF(algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=False)Evaluation Metrics
It is essential that the model is evaluated by these metrics per class to make sure we have a good model.
정밀도(precision), 재현율(recall), F1-score를 이용해 성능을 평가하며, 문장 단위가 아닌 토큰(token) 단위로 평가한다.
Since we are dealing with Information Extraction, we will use the following metrics to evaluate the models -
- Precision (TP/TP+FP)
- Recall (TP/TP+FN)
- F1 score (2∗(Recall∗Precision)/(Recall+Precision))
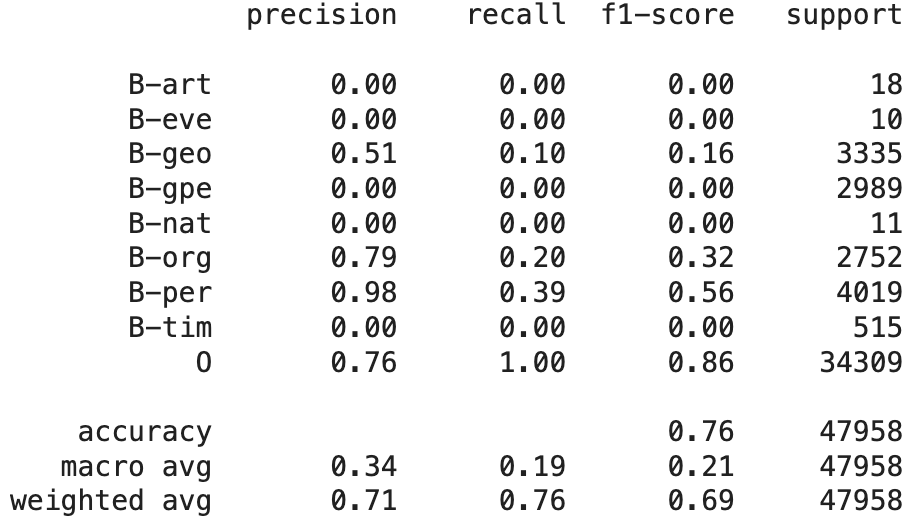
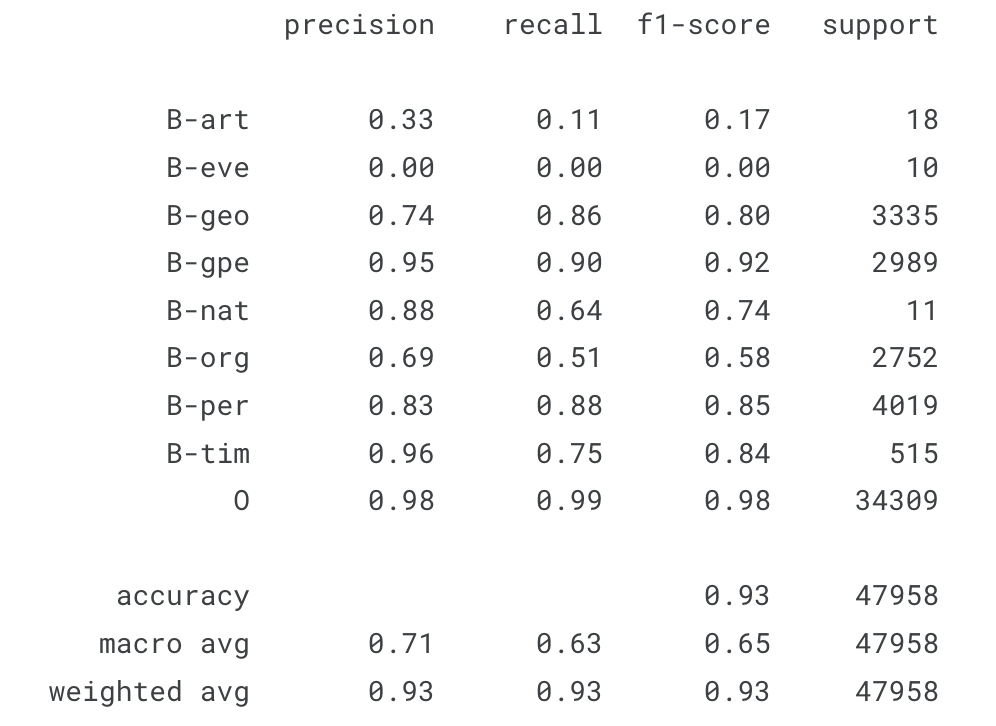
Random Forest 분류기에 비해 CRF 분류기는 점수가 향상되면서 더 나은 성능을 보여주는 것을 확인했지만, 클래스 개별적으로 정밀도와 재현율 지표는 많이 향상되지 않았다. 이는 단어를 기억하고 맥락 정보를 받아들이는 과정에서 모델이 제대로 학습되지 않았을 것으로 추측된다.
[Practice Code]
https://github.com/juooo1117/practice_AI_Learning/blob/main/NamedEntityRecognition_with_CRF.ipynb
'Artificial Intelligence' 카테고리의 다른 글
| Word Embeddings - word2vec, Skip-Gram Model (0) | 2023.12.14 |
|---|---|
| Text Summarization (0) | 2023.12.14 |
| Movie genres - Clustering practice with NMF (0) | 2023.12.14 |
| Text Classification - Sentiment Analysis (0) | 2023.12.13 |
| Text Clustering - NMF & Mini Batch k-means (0) | 2023.12.12 |



