
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- textmining
- ResNet
- AI 윤리
- cross domain
- gaze estimation
- Transfer Learning
- nlp
- Generative model
- NMF
- LSTM
- Support Vector Machine
- Logistic Regression
- Gradient Descent
- Attention
- tensorflow
- Clustering
- MLOps
- RNN
- TFX
- Binary classification
- SOMs
- 자기조직화지도
- BERT
- 경사하강법
- NER
- Python
- stemming
- 군집화
- VGGNet
- Ann
- Today
- Total
juooo1117
RT-GENE: Real-Time Eye Gaze Estimation in Natural Environments 본문
RT-GENE: Real-Time Eye Gaze Estimation in Natural Environments
Hyo__ni 2025. 3. 20. 23:40Paper Review
RT-GENE: Real-Time Eye Gaze Estimation in Natural Environments
(Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 334-352)
Abstract
Two main shortfalls in sota methos for gaze estimation:
hindered ground truth gaze annotation and diminished gaze estimation accuracy as image resolution decreases with distance.
Proposed Approach:
We first record a novel dataset of varied gaze and head pose images in a natural environment, addressing the issue of ground truth annotation by measuring head pose using a motion capture system and eye gaze using mobile eyetracking glasses.
(새로운 데이터셋 구축!)
We apply semantic image inpainting to the area covered by the glasses to bridge the gap between training and testing images by removing the obtrusiveness of the galsses.
(안경으로 가려지는 부분을 복원해서 train/test data 의 차이를 없애서 → 학습이 잘 되게 함)
We present new real-time algorithm involving appearance-based deep convolutional neural networks with increased capacity to cope with the diverse images in the new dataset.
(CNN 기반의 real-time 알고리즘 만듦)
Introduction
this work is the first to address gaze estimation in natural settings with larger camera-subject distances and less constrained subject motion. Our novel approach involves automatically annotating ground truth datasets by combining a motion capture system for head pose detection, with mobile eye tracking glasses for eye gaze annotation.

this setup directly provides the gaze vector in an automated manner under free-viewing conditions, which allows rapid recording of the dataset.
Since we are interested in estimating the gaze of subjects without the use of eyetracking glasses, it is important that the test images are not affected by an alteration of the subjects' appearance. → For this purpose, we show that semantic image inpainting can be applied in a new scenario, namely the inpainting of the area covered by the eyetracking glasses. The images with removed eyetracking glasses are then used to train a new gaze estimation framework. (트래킹 안경을 지우는 것이 포인트!)

1) Motion Capture System : Eyetracking Glasses, RGB-D 카메라의 motion capture marker 사용해서 Head Pose 측정
2) Eyetracking Glasses : head pose 에 대한 Eye Gaze Vector 를 측정해서, 이것을 학습 데이터의 label 로 사용!
3) Semantic Image Inpainting : 얼굴 영역만 골라내서, 안경을 제거!
4) Facial Landmark Detection : 얼굴에서 5개의 주요 랜드마크 검출 후, → gaze estimation 을 위해서 eye patch 이미지 생성
5) Gaze Estimation Network : 라벨링한 Eye Gaze Vector 과 eye patch 를 입력으로 해서 학습 진행
Gaze Dataset Generation
Eye gaze annotation:
We use a customized version of the Pupil Labs eyetracking glasses. In our dataset with significantly larger distances, we obtain an angular accuracy of 2.58 +- 0.56 degrees.
Coordinate transform:
eye gaze vector 'g' 는 eyetracking frame 'Fe' 좌표계에서 정의되어 있는데, 이를 RGB-D 카메라의 visual frame 'Fc' 좌표계로 변환시켜야 됨. → 따라서 시선 좌표 변환(Coordinate Transforms)이 필요함!!
To find 'Tc→c∗', we use the property of RGB-D cameras which allows to obtain 3D point coordinates of an object in the visual frame 'Fc'. If we equip this object with markers tracked by the motion capture system, we can find the corresponding coordinates in the motion capture frame 'Fc∗'.
(모션 캡처 시스템이 추적하는 marker 좌표를 이용해서 RGB-D 카메라 좌표계와 정렬시키는 것)
By collecting a sufficiently large number of samples, the Nelder-Mead method can be used to find 'Tc→c∗' .
(이 방법을 사용해서 변환행렬을 계산한다!)
To find 'Te→e∗', as we have a 3D model of the eyetracking glasses, we use the accelerated iterative closest point algorithm to find the transform 'Te→e∗' between the coordinates of the markers within the model and those found using the motion capture system.
(위 알고리즘을 사용하여 모션 캡처 시스템이 측정한 marker 좌표와, eyetracking 안경의 3D 모델 좌표를 정렬해서 두 좌표계 간의 변환행렬을 찾음)
ICP(Iterative Closest Point): 두 개의 3D Point Cloud를 정렬하는 알고리즘으로, 두 Point Cloud사이의 변환 행렬(회전 + 이동)을 찾는 과정이다.
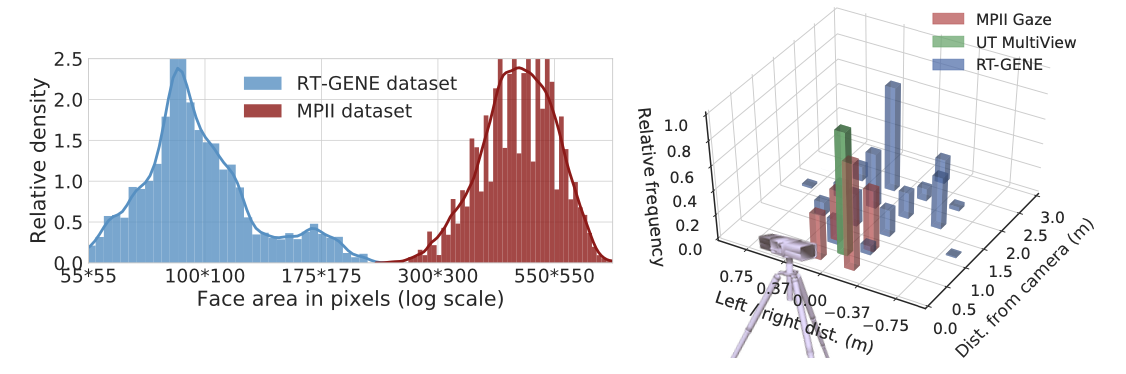
Dataset statistics:
The proposed RT-GENE dataset contains recordings of 15 participants, with a total of 122,531 labeled training images and 154,755 unlabeled images of the same subjects where the eyetracking glasses are not worn.
The free-viewing task leads to a wider spread and resembles natural eye behavior, rather than that associated with mobile device interaction or screen viewing as in other dataset.
(기존 데이터셋들은 모바일 기기 사용 또는 화면 보기 중심인 반면, 이 데이터는 자연스러운 시선을 반영함.)
The camera-subject distances range between 0.5m and 2.9m, with a mean distance of 1.82m
(카메라와 사람 사이의 거리가 멀어서, 자연스럽게 시선을 추정할 수 있다.)
the area covered by the subjects’ faces is much lower in our dataset (mean: 100 × 100 px) compared to other datasets (MPII Gaze dataset mean: 485 × 485 px).
(다른 데이터셋에 비해서 사람 얼굴 크기가 작다. → 따라서 더 먼 거리에서 시선추정이 가능함)
Removing Eyetracking Glasses
We adopt this GAN-based image inpainting approach by considering both the textural similarity to the closely surronding area and the image semantics. (this is the first work using semantic inpainting to improve gaze estimation accuracy)
Masking eyetracking glasses region:
The CAD model of the eyetracking glasses is made up of a set of N = 2662 vertices (3D 좌표)
To find the target region to be inpainted, we use 'Te→c' to derive the 3D position of each vertex in the RGB-D camera frame.
(변환 행렬을 이용해서각 Vertex의 3D 좌표를 RGB-D 카메라 좌표로 변환함)
For extreme head poses, certain parts of the eyetracking glasses may be obscured by the subject’s head, thus masking all pixels would result in part of the image being inpainted unnecessarily.
(일부 안경 영역이 가려질 수도 있다. 따라서 모든 부분을 마스킹하면, 가려진 부분이 불필요하게 복원될 수 있음)
To overcome this problem, we design an indicator function, which selects vertices 'Vn' of the CAD model if they are within a tolerance 'τ' of their corresponding point 'Pn' in the depth field.
(인디케이터 함수를 써저 특정 임계값을 설정함, → 이 값 내에 있는Vertex만 마스킹을 적용한다.)

Semantic inpainting:
To fill the masked regions of the eyetracking glasses, we use a GAN-based image generation approach.
Our proposed architecture allows the inpainting of images with resolution 224×224px. This is a crucial feature as reducing the face image resolution for inpainting purposes could impact the gaze estimation accuracy.
(GAN을 기반으로 자연스럽고 정밀한 복원 작업을해서, gaze estimation 정확도를 유지함!)
We trained a separate inpainting network for each subject 'i'.
Let 'Di' denote a discriminator that takes as input an image 'Xi' ∈ Rd (d = 224×224×3) of subject 'i' from the dataset where the eyetracking glasses are not worn, and outputs a scalar representing the probability of input 'Xi' being a real sample.
(각각 실험자마다 다른 복원 모델을 학습함. Discriminator의 입력은 안경이 없는 실제 이미지, 출력은 입력 이미지가 실제(real)인지, 생성(fake)된 것인지 확률 값으로 반환함)
We use a least squares loss, which has been shown to be more stable and better performing, while having less chance of mode collapsing.
Poisson blending is then applied to inpainted result in order to generate the final inpainted images with seamless boundaries between inpainted and not inpainted regions.
(복원된 영역과 기존 이미지의 경계가 부자연스럽지 않도록 Poisson Blending 적용)
Gaze Estimation Networks
the gaze estimation is performed using several networks.
Firstly, we use Multi-Task Cascaded Convolutional Networks (MTCNN) to detect the face along with the landmark points of the eyes, nose and mouth corners. (얼굴 랜드마크 검출)
Using the extracted landmarks, we rotate and scale the face patch so that we minimize the distance between the aligned landmarks and predefined average face point positions to obtain a normalized face image using the accelerated iterative closest point algorithm. (검출한 얼굴 랜드마크를, 미리 정의된 평균의 얼굴 포인트들과 최대한 일치하도록 이미지를 rotate, scale 해서 맞춤 → 이를 통해 학습 데이터의 일관성을 유지 가능)
We then extract the eye patches from the normalized face images as fixed-size rectangles centered around the landmark points of the eyes. (눈 영역만 고정된 크기로 잘라냄 → eye patch image)
Secondly, we find the head pose of the subject by adopting the state-of-the-art method presented by Patacciola et al.
Proposed eye gaze estimation:
The eye patches are fed separately to VGG-16 networks which perform feature extraction.
Each VGG-16 network is followed by a fully connected (FC) layer of size 512 after the last max-pooling layer, followed by batch normalization and ReLU activation.
(input data(eye patches)는 왼쪽눈, 오른쪽눈 각각 따로 VGG-16 모델을 통과하며, 모델은 max-pooling layer → FC layer(512) → BatchNorm → ReLU 구조임.)
We then concatenate these layers, resulting in a FC layer of size 1024. This layer is followed by another FC layer of size 512.
- 왼쪽 눈(512) + 오른쪽 눈(512) → 1024 차원의 벡터로 결합(Concatenation)
- 즉, 두 눈에서 추출된 정보를 하나의 벡터로 통합하는것
- 결합된 벡터(1024)를 FC Layer(512)로 변환
We append the head pose vector to this FC layer, which is followed by two more FC layers of size 256 and 2 respectively. The outputs of the last layer are the yaw and pitch eye gaze angles.
- FC Layer(512) 후에 Head Pose 벡터 추가 + FC Layer(256) 추가 + FC Layer(2) 추가
- output → Yaw & Pitch Eye Gaze Angles (시선 방향의 두 가지 각도)
For increased robustness, we use an ensemble scheme where the mean of the predictions of the individual networks represents the overall prediction.
(각 네트워크의 예측값의 평균을 최종적으로 사용)
Image augmentation:
we augment the training images in four ways.
1) Handling Off-Centered Eye Patches
- 랜드마크 추출할 때 발생하는 오차를 보완하고자, crop → resizing it back to original 하는 과정으로 이미지를 10번 증강한다.
- 4 테두리에서 0~5 픽셀 사이의 크기로 랜덤하게 crop 하는 방식을 사용.
- 결과적으로 하나의 원본 이미지에 대해 10개의 Augmented Images 생성.
2) Robustness Against Camera Blur
- 카메라 해상도 저하에 영향을 받지 않도록 하기 위해서, 해상도를 원본의 1/2, 1/4로 Downscaling.
- 이후, Bilinear Interpolation(쌍선형 보간)을 이용하여 다시 원래 크기로 Upscaling.
3) Covering Various Lighting Conditions
- 다양한 조명 조건에서도 성능을 유지하기 위해서 histogram equalization 적용
4) Convert Color images to Gray-scale
- 컬러 정보가 부족한 환경에서도 시선 추정이 가능하도록 일반화 한 것
Conclusion and Future Work
We proposed RT-GENE, a novel approach for ground truth gaze estimation in these natural settings, and we collected a new challenging dataset using this approach. We demonstrated that the dataset covers a wider range of camera-subject distances, head poses and gazes compared to previous in-the-wild datasets.
We have shown that semantic inpainting using GAN(안경 없애는 것!) can be used to overcome the appearance alteration caused by the eyetracking glasses during training. The proposed method could be applied to bridge the gap between training and testing in settings where wearable sensors are attached to a human (e.g. EEG/EMG/IMU sensors)
Our proposed method achieved sota performance on the MPII Gaze dataset (10.4% improvement), UT Multi-view (13.6% improvement), our proposed dataset (11.5% improvement), and in cross dataset evaluation (22.4% improvement).
Future Work
We will investigate gaze estimation in situations where the eyes of the participant cannot be seen by the camera. (카메라에 눈이 보이지 않을때도 시선 추정을 할 수 있도록)
As our dataset allows annotation of gaze even in these diverse conditions, it would be interesting to explore algorithms which can handle these challenging situations. We hypothesize that saliency information of the scene(장면의 주목도; 즉, 시선이 보이지 않아도 장면 내에서 주목할 만한 위치를 기반으로 시선을 추정) could prove useful in this context.
'Artificial Intelligence > Research Paper' 카테고리의 다른 글
| Source-free Adaptive Gaze Estimation by Uncertainty Reduction (0) | 2025.03.25 |
|---|---|
| MoST: Motion Style Transformer between Diverse Action Contents (0) | 2025.03.19 |
| Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs (0) | 2025.03.01 |
| Cross domain - Medical Image Segmentation (0) | 2025.02.03 |
| Cross-domain Image Analysis - Domain Shift (0) | 2025.02.03 |



