
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Support Vector Machine
- 자기조직화지도
- Logistic Regression
- LSTM
- RNN
- cross domain
- stemming
- Binary classification
- Attention
- VGGNet
- Python
- Transfer Learning
- NER
- Generative model
- Gradient Descent
- 경사하강법
- nlp
- SOMs
- NMF
- Clustering
- textmining
- tensorflow
- BERT
- Ann
- gaze estimation
- 군집화
- ResNet
- AI 윤리
- MLOps
- TFX
- Today
- Total
juooo1117
[Module 6] Deep Learning: Self-Supervised Learning & Pre-Trained Models 본문
[Module 6] Deep Learning: Self-Supervised Learning & Pre-Trained Models
Hyo__ni 2024. 1. 14. 14:29Part 6. Self-Supervised Learning and Large-Scale Pre-Trained Models
Self-Supervised Learning?
: Given unlabeled data, hide part of the data and train the model so that it can predict such a hidden part of data, given the remaining data.
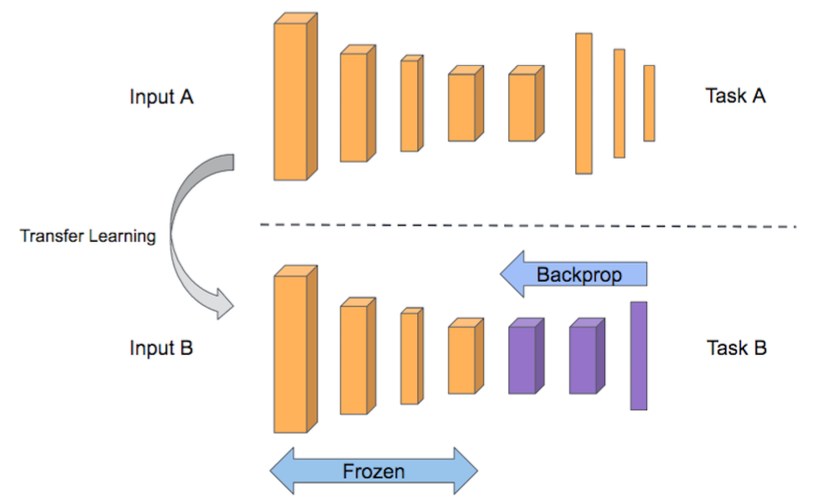
Transfer Learning from Self-Supervised Pre-trained Model
Pre-trained models using a particular self-supervised learning can be fine-tuned to improve the accuracy of a given target task.
BERT : pre-training of Deep Bidirectional Transformers for Language Understanding (paper 제목!)
- Lean through masked language modeling and next-sentence prediction tasks.
- Use large-scale data and large-scale model.

transformer encoder 기반의 BERT model architecture는 자가지도학습이라는 task의 형태로 학습시키기 위해서 대규모의 text data를 학습 data로 사용한다.
주어진 입력 문장을 BERT 모델의 입력 sequence로 제공해 주되 입력 data의 일부를 가리고 그것을 예측하도록 하는 과정에서(; self-supervised learning) 입력 문장에서 일부 단어들을 mask 라는 special token으로 대체를 하고 mask token 자리에 원래 무슨 단어가 있어야 했는지를 맞추도록 하는 task로 이 모델을 학습하게 됨.
Pre-Training Tasks of BERT
Masked Language Model (MLM)
- Mask some percentage of the input tokens at random, and then predict those masked tokens.
- 15% of the words to predict (80% of the time, replace with 'mask' / 10% of the time, replace with a random word / 10% of the time, keep the sentence as same)
Next Sentence Prediction (NSP)
- Predict whether Sentence B is an actual sentence that proceeds Sentence A, or a random sentence.
GPT-1/2/3: Generative Pre-Trained Transformer
Generative Pre-Training Task
- In other words, this task is called Language Modeling.
- From another perspective, this task is called an Auto-Regressive Model, in a sense that the predicted output at the current time step will be used as an input at the next time step.

GPT-2
Language Models are Unsupervised Multi-task Learners
Just a really big transformer-based language model
- Trained on 40GB of text
- A large amount of efforts have been put to secure a high-quality dataset.
- Take webpages from reddit links with at least 3 karma (up-vote)
Language models can perform down-stream tasks in a zero-shot setting – without any parameter or architecture modification.
GPT-3
Language Models are Few-Shot Learners
- Scaling up language models greatly improves task-agnostic, few-shot performance.
- An autoregressive language model with 175 billion parameters in the few-shot setting.
- 96 attention layers, batch size of 3.2M, 175B parameters

Few-shot learning e.g. of GPT-3
- Prompt: the prefix given to the model.
- Zero-shot: Predict the answer given only a natural language description of the task.
- One-shot: See a single example of the task in addition to the task description.
- Few-shot: See a few examples of the task.

[summary]
Models are getting bigger and bigger.
Owing to self-supervised learning techniques, the language generation capability is getting better and better.
We are getting closer to artificial general intelligence.
'Artificial Intelligence > LG Aimers: AI전문가과정' 카테고리의 다른 글
| [Module 8] B2B 고객 행동 예측 방법론 (0) | 2024.01.19 |
|---|---|
| [Module 5] 인과추론: Causality (1) | 2024.01.14 |
| [Module 6] Deep Learning: Transformer (1) | 2024.01.14 |
| [Module 6] Deep Learning: Seq2Seq with Attention for Natural Language Understanding and Generation (0) | 2024.01.13 |
| [Module 6] Deep Learning: CNN and Image Classification (0) | 2024.01.12 |



