
Natural Language Processing(NLP, 자연어처리)
NLP is concerned with developing computational techniques to enable a computer to understand the meaning of natural language text. NLP may involve the following tasks;
- Lexical analysis(어휘분석) :
주어진 언어에서 의미를 갖는 기본 단위들을 찾아내고(ex. whitespace, 단어..) 그것들의 의미를 파악한다
품사 태깅(POS, Part-of-speech tagging)
- Syntactic analysis(구문분석) :
주어진 문장에서 단어들이 어떻게 서로 연결되는지 파악하고 문장에서의 구문 구조를 밝혀내는 것
구문 트리(Parsing → Parse tree)
- Semantic analysis(의미론적 분석) :
문장의 의미를 파악하는 것 → 추론(inference)
- Pragmatic analysis(화용론적 분석) :
문맥에서의 의미를 파악하고 그 문장을 사용한 의도를 밝혀내는 것
문장의 화자가 담고 있는 의도를 알아낸다.
- Discourse analysis(담화분석) :
문장들 간의 관계 등을 분석하여 담화의 구조와 의미를 파악하는 것
자연어 처리 순서: 문자열 → 단어 시퀀스 → POS tagging → 구문분석 → 개체와의 관계확인 → 논리 서술 → 화자의 의도
자연어는 인간의 커뮤니케이션을 위해 만들어진 언어이므로, 컴퓨터에 의한 자연어 처리가 매우 어렵다.
⇒ WSD(Word-sense disambiguation, 단어의미 명확화) 필요
Text data processing Steps
- Tokenization(토큰화) : 문자열에서 단어로 분리
- Stopword elimination(불용어 제거) : 전치사, 관사, 빈도수가 높은 단어 등 문장이나 문서의 특징을 표현하는 데 불필요한 단어 삭제 → 먼저 소문자화하고, 불용어 사전을 이용!!
- Stemming(어간추출) : 단어의 기본 형식을 추출 (ex. 복수형 단어의 단수화, 동사의 기본형…) → 다양한 알고리즘 존재. 기본형으로부터 단어들을 자동으로 파생시켜서 리스트를 만들고 매칭시키기도 함.
- Representation(문서표현) :
주어진 문서나 문장을 하나의 벡터로 표현함. 단어들을 모두 인덱싱하고 주어진 문서에 존재하는 단어의 빈도수를 사용하여 그 문서를 표현함
- Bag-of-words model → 문서가 단어의 집합이라 가정하고, 단어의 순서는 고려하지 않음
- Vector space model → 사전으로부터 각 단어의 index를 찾고 문서(문장) 내에서의 빈도수를 세어 벡터로 표현함 (문서간 거리계산: Euclidean distance, Cosine similarity)

programing, presidential, library 단어를 vector로 나타냄 - Sparse data representation(희소표현) → 데이터를 벡터 또는 행렬 기반으로 수치화하여 표현할 때 극히 일부의 인덱스만 특정 값으로 표현하고, 나머지 대부분의 인덱스는 의미 없는 값으로 표현하는 기법. 대표적으로 One-Hot Encoding 방식이 있다.
사전(Vocab Dictionary) 만들기
단어와 단어에 대한 인덱스가 표시된 사전
단어 자체를 사용하여 문서를 표현하면 비효율적이다.
문서 집합에 있는 문서 전체를 읽어가면서 단어를 토큰화 → 불용어제거 → 어간추출하여 사전을 구축
corpus(말뭉치) ⇒ 자연어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합
TF-IDF(Term Frequency - Inverse Document Frequency)
단순히 빈도로 문서를 표현하는 것이 아니라, 단어의 중요도를 고려해서 새로운 수치로 바꾸어서 표현한다.
Term Frequency: tf(t,d), 특정문서 ‘d’에서 특정 단어 ‘t’가 등장한 횟수
- 실제 빈도수 → tf
- 0, 1 값으로 사용 가능
- 로그정규화 1 + log(tf) → 로그 정규화해서 사용 가능
Inverse Document Frequency: idf(t, D), 한 단어가 문서집합(D)에서 얼마나 공통적으로 나타나는지
- IDF 로그 함수 안의 값은 항상 1이므로, IDF값과 TF-IDF값은 항상 0 이상이 된다.
- 특정 단어를 포함하는 문서들이 많을 수록 log안의 값이 1에 가까워지므로, IDF값과 TF-IDF값은 0에 가까워지게 된다.
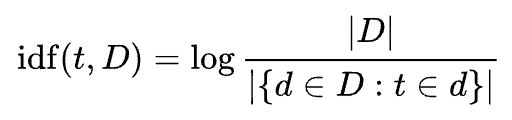
TF-IDF: 특정 문서 내에서 단어의 빈도가 높을 수록, 전체 문서들 중 그 단어를 포함한 문서가 적을수록 TF-IDF 값이 높아진다. 따라서 이 값을 사용하면 모든 문서에 흔하게 나타나는 단어를 걸러낼 수 있다.
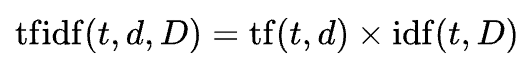
N-gram Language Model
n-gram 언어모델은 count에 기반한 통계적 접근을 사용하고 있으므로 SLM(Statistical Language Model, 통계적 언어모델)의 일종이다. 단, 등장하는 모든 단어를 고려하는 것이 아니라 일부 단어만 고려하는 접근 방법을 사용하는데, n-gram에서 ‘n’이 가지는 의미가 일부의 단어를 몇 개 볼 것인지를 결정하는 계수이다.
n-gram은 n개의 연속적인 단어의 나열을 의미한다. 가지고 있는 corpus에서 n개의 단어 뭉치 단위로 끊어서 이를 하나의 token으로 간주한다.
example) An adorable little boy is spreading smiles
- unigrams : an, adorable, little, boy, is, spreading, smiles
- bigrams : an adorable, adorable little, little boy, boy is, is spreading, spreading smiles
- trigrams : an adorable little, adorable little boy, little boy is, boy is spreading, is spreading smiles
- 4grams : an adorable little boy, adorable little boy is, little boy is spreading, boy is spreading smiles
일반적으로 n-gram을 만드는 경우, 단어를 겹치게 하여 모든 경우를 구한다. 즉, n개의 단어로 이루어진 윈도우를 한 단어씩 이동하며 n-grams를 구성한다.
Morphological Analysis(형태학적 분석)
Morphology(형태론)
단어의 어형변화를 다루는 문법의 한 분야로 ‘어형론’이라고도 하며, 형태소를 분석하고 형태소들 간의 상관관계를 규명함 (형태소 → 뜻을 가진 가장 작은 말의 단위)
- Inflectional morphology(굴절 형태론): 문법적인 사용에 따라 단어가 변함 → ex) say-said / cat-cats
- Derivational morphology(파생 형태론): 한 단어로부터 관련된 의미를 갖는 새로운 단어들을 생성 → ex) organize-organization-organizational
- Compounding(합성): 새로운 단어를 생성하기 위해 단어들을 합성함 → ex) shipwreck, outbound, beefsteak
⇒ 굴절(문법적 사용)되고 파생(관련된 의미)된 단어들은 같은 인덱스(word)로 만들자
형태소분석
단어를 형태소 단위로 분리하고, 어근, 접두사/접미사, 품사 등의 언어적 속성을 파악하는 과정을 의미한다
Conflation(융합): 굴절되고 파생된 단어들을 같은 index의 단어로 만듦 → 중요하지 않은 단어 변형을 무시할 수 있게 한다.
영어에서는 단어 변형이 단어의 끝부분에서 이루어지기 때문에 주로 접미사를 제거하는 stemming(어간추출)을 통해 이 작업을 수행함
NLTK에서 제공하는 Porter Stemmer(어간추출기)
import nltk
from nltk.stem import LancasterStemmer, PorterStemmer, RegexpStemmer, RSLPStemmer
stemmer = PorterStemmer()
stemmer.stem('saying') # output: say

